



ปัจจุบันพบความท้าทายในการเข้าถึงเอกสาร PDF โดยกว่า 90% ของเอกสาร PDF ทั่วโลกไม่รองรับการใช้งานสำหรับบุคคลที่มีความทุพพลภาพ นอกจากนี้ยังพบปัญหาอื่น ๆ เช่น หน้าเปล่า ข้อความไม่ชัด บรรทัดบิดเบี้ยว หรือแม้แต่ตำแหน่งของตัวอักษร สระ วรรณยุกต์ นอกจากนี้ยังมีกรอบการใช้งานที่องค์กรและผู้ใช้ต้องปฏิบัติตามกฎระเบียบของรัฐบาลและความคาดหวังของผู้ใช้ โดยการอัปเดตครั้งนี้ รองรับการทำงานให้ครอบคลุมผู้ใช้งานและกฎระเบียบได้ดียิ่งขึ้น
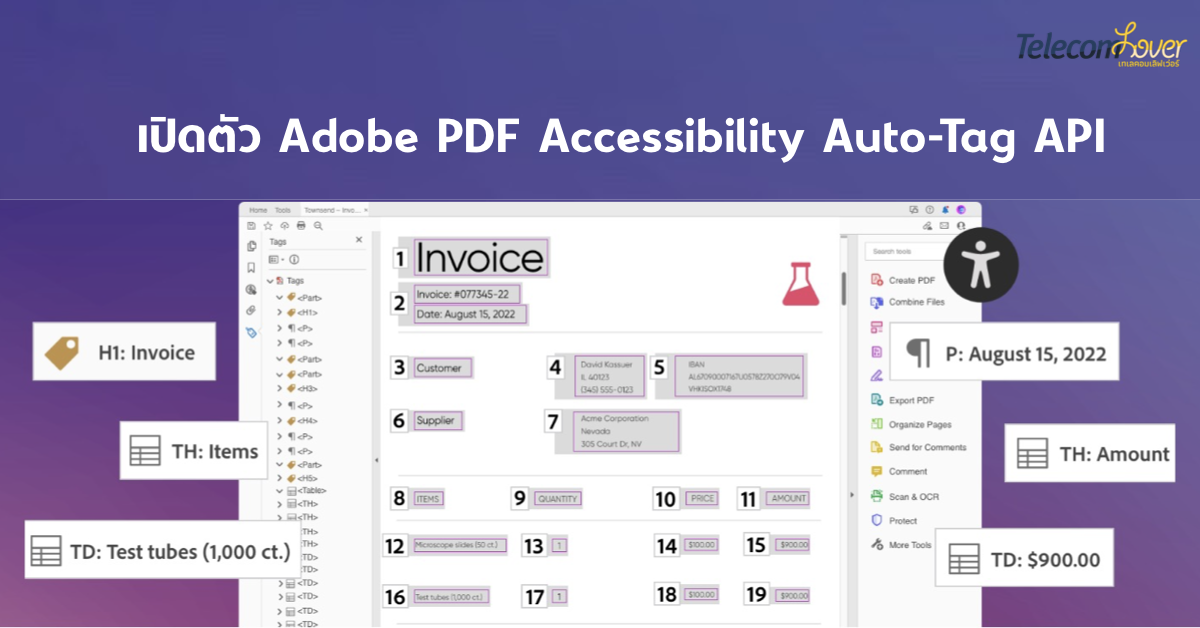
- Adobe PDF Accessibility Auto-Tag API: Adobe ได้เปิดตัว API ใหม่ที่ขับเคลื่อนโดย Adobe Sensei ซึ่งเป็นเฟรมเวิร์ก AI และแมชชีนเลิร์นนิง เพื่อลดความซับซ้อนและเร่งกระบวนการแปลงเนื้อหา PDF API มีจุดมุ่งหมายเพื่อทำให้เอกสาร PDF สามารถเข้าถึงได้มากขึ้น ประหยัดเวลา ปรับปรุงการปฏิบัติตามกฎหมาย และเพิ่มประสบการณ์ของพนักงานและลูกค้า
- อัตโนมัติมากขึ้นและประหยัดเวลามากขึ้น: ในอดีต การทำให้เอกสาร PDF สามารถเข้าถึงได้นั้นเป็นกระบวนการที่ต้องทำด้วยตนเองและใช้เวลานาน อย่างไรก็ตาม ผู้ทดลองใช้กลุ่มแรก ๆ ของ Adobe PDF Accessibility Auto-Tag API สามารถดำเนินการโดยอัตโนมัติได้เร็วขึ้น 70% ซึ่งช่วยลดเวลาที่จำเป็นในการทำให้แต่ละไฟล์สามารถเข้าถึงได้อย่างเต็มที่ถึง 100% โดย API มีประสิทธิภาพโดยเฉพาะอย่างยิ่งสำหรับเอกสารที่ซับซ้อน ลดเวลาที่จำเป็นสำหรับงานต่าง ๆ เช่น การเข้าถึงชุดสไลด์การนำเสนอได้อย่างมาก
- ใช้ประโยชน์จาก AI: API ของ Adobe ใช้ AI เพื่อทำให้การแท็กโครงสร้างเนื้อหา PDF แบบอัตโนมัติ เช่น หัวเรื่อง ย่อหน้า รายการ และตาราง การติดแท็กนี้ช่วยให้แน่ใจว่าจะสามารถจัดลำดับการอ่านบนเทคโนโลยีได้อย่างเหมาะสม เช่น โปรแกรมอ่านหน้าจอ ที่รองรับการใช้งานสำหรับบุคคลทุพพลภาพ นอกจากนี้นักพัฒนาสามารถใช้ API จัดการกับเอกสาร PDF ที่มีอยู่จำนวนมากได้อย่างรวดเร็ว รวมทั้งช่วยให้ปฏิบัติตามกฎระเบียบด้านการเข้าถึงได้อย่างมีประสิทธิภาพ
- คุณสมบัติเพิ่มเติมและความก้าวหน้าของความสามารถในการเข้าถึง: ตัวตรวจสอบการเข้าถึง PDF ซึ่งช่วยให้บริษัทต่าง ๆ ประเมินการเข้าถึง PDF ที่มีอยู่ได้อย่างมีประสิทธิภาพ และแท็กอัตโนมัติใน Acrobat Reader ซึ่งมอบประสบการณ์การใช้งานที่เข้าถึงได้มากขึ้นภายในแอปพลิเคชัน เป็นสองฟีเจอร์ใหม่ที่ Adobe วางแผนที่จะเปิดให้บริการ

